I’ve recently created a learning log for this year (2025). The first topic that I wanted to go over is dbt (data-build-tool). Here are some of my notes. I’m putting more materials or notes here about dbt as I go along.
To start, I’ve taken a Udemy course The Complete dbt (Data Build Tool) Bootcamp: Zero to Hero as an introduction to dbt. Here is the repo where I’ve been doing the hands-on throughout the course: dbtlearn. I’ve started the course on Jan 24, and finished on Feb 2. (Sharing my certificate). I’m hoping these notes would be a good reference in the future.
dbt and Snowflake setup
Here’s what I did for the setup:
- Created a Snowflake trial account. It’s good for 30 days with $400 credit.
- Setup Snowflake warehouse and permissions for
dbt, ingested Airbnb data hosted in AWS S3 into the raw tables. - In my local machine, installed Python 3.12.7 (I needed to downgrade from Python 3.13.0 as it’s not yet supported by dbt). I also installed
virtualenv using Homebrew but I realized I could have just installed it using pip. - Installed
dbt-snowflake in the virtual environment (always use a Python virtual environment!) - Created a dbt user directory
mkdir ~/.dbt - Initialized dbt project (
dbt init dbtlearn) and connected it to the Snowflake account. I also learned just to delete the project directory when deleting a project (I made a configuration mistake! :p) - Updated
dbt_project.yml to remove examples; deleted examples from the project directory - Installed dbt plugin “Power User for dbt core” in VS Code and set it up.
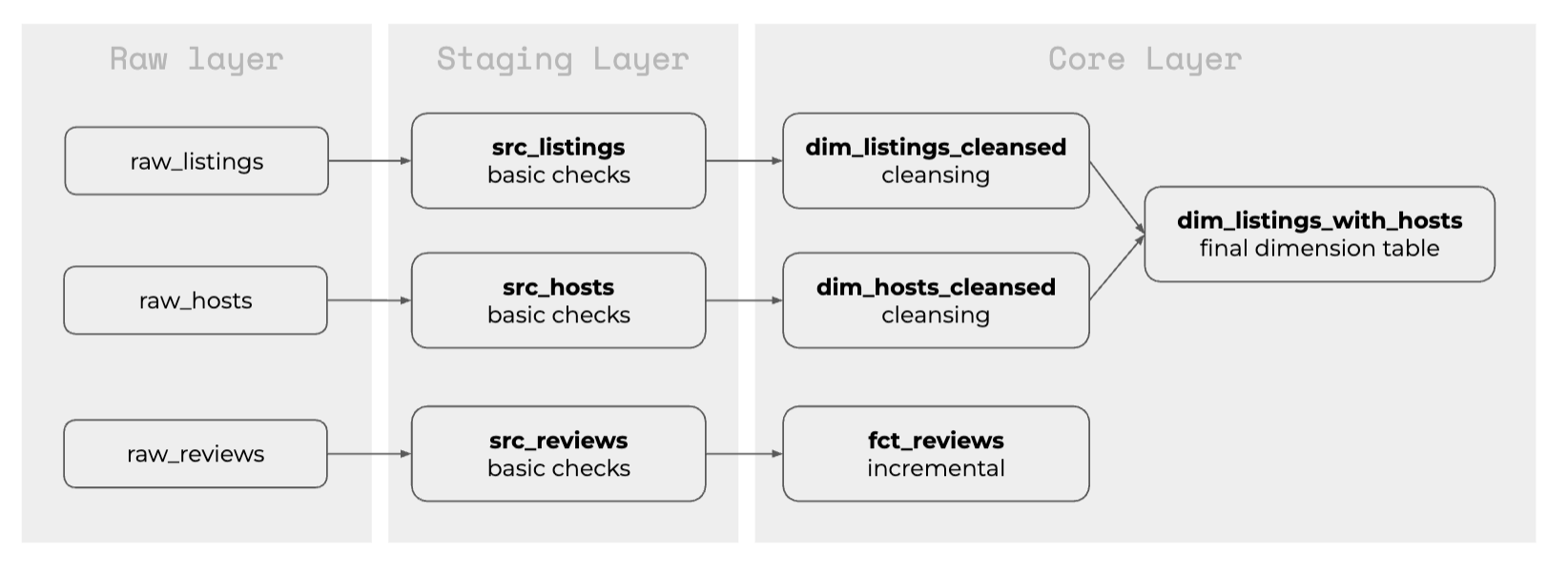
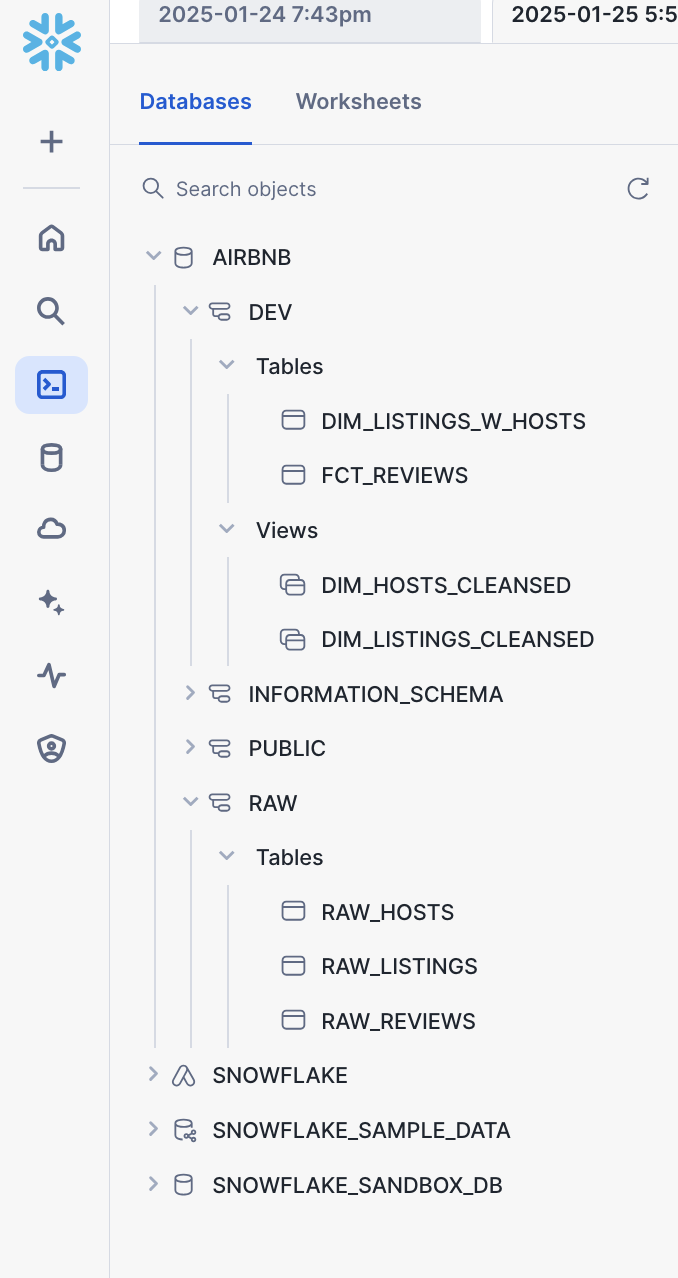
Models and materialization
Here’s the final outcome in the data warehouse
The project YAML file has been modified to follow these defaults; the + sign before +materialized means that it’s a dbt keyword and not a directory
1
2
3
4
5
6
7
| models:
dbtlearn:
+materialized: view
dim:
+materialized: table
src:
+materialized: ephemeral
|
The following configuration was added for the the two dim tables so they materialized as views instead of tables, overriding the default state in the project YAML.
1
2
3
4
5
| {{
config(
materialized = 'view'
)
}}
|
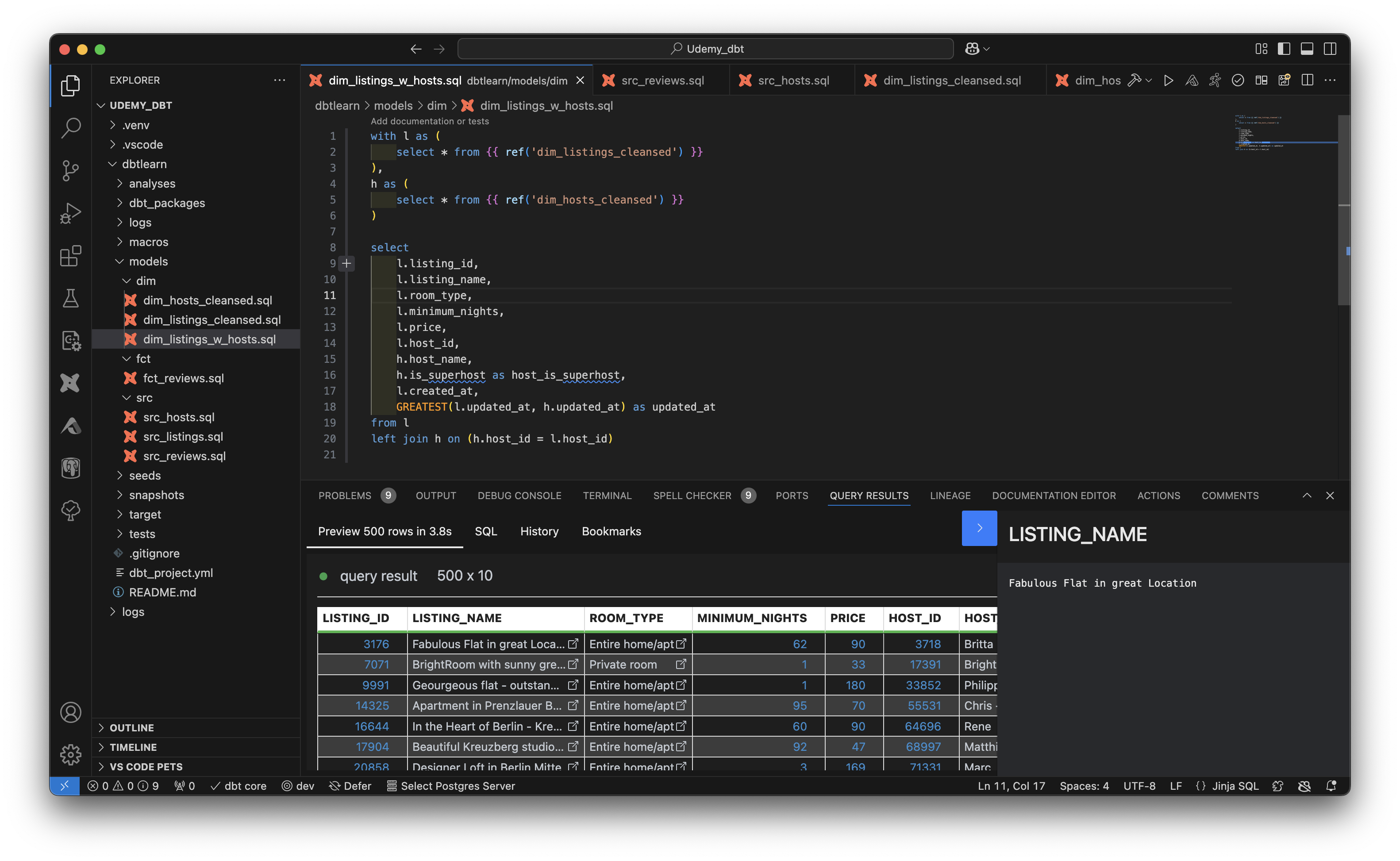
Using the dbt plugin was also convenient in that when testing the SQL, I only needed to run it within the editor and it’s able to return the results of the query (no need to switch into Snowflake’s interface). It can also be used to build the model using GUI.
dbt models are SQL definitions that can be materialized (or not) into tables or views. These are stored as SQL files under dbtlearn/models/. They consist of select statements but contain other features such as: semantic dependencies with other models, scripts and macros.
dbtprpoject/target/run/dbtlearn/models - contains the final compiled models. Files here can be investigated when troubleshooting.
CTE (common table expressions) are widely used and recommended as they are readable, easy to maintain, and make complex queries readable. They are similar to views but are not stored
Commands to build models include:
dbt run - materializes the modelsdbt run --full-refresh - rebuilds all tables including incremental tables
There are four (4) types of materialization in dbt
| type | use | don’t use |
|---|
| view | light weight representation;
the model isn’t being reused often | the model is being read several times |
| table | the model is being read repeatedly | single-use models; incremental load |
| incremental | fact, event tables;
appends to tables | update historical records |
| ephemeral | i.e. no materialization;
want to use an alias to a column | model is read several times |
Here’s an example of a dbt model using an incremental load, and Jinja
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| {{
config(
materialized = 'incremental',
on_schema_change = 'fail'
)
}}
with src_reviews as (
select * from {{ ref('src_reviews') }}
)
select * from src_reviews
where review_text is not null
{% if is_incremental() %}
and review_date > (select max(review_date) from {{this}})
{% endif %}
|
When switching from a materialized model to an ephemeral model, delete the tables manually in the data warehouse as dbt won’t delete the tables or views itself.
Seeds
- local files yet to be uploaded to the warehouse using dbt
- contained in this path
dbtlearn/seeds e.g. dbtlearn/seeds/seed_full_moon_dates.csv - in the project YAML file, the paths of seeds are defined as
dbt seed command populates seed in Snowflake; this results in a table. (Snowflake can infer the column schema from file)
Source
- an abstraction layer that sits on the top of the input (raw) tables e.g. those defined in models
/dbtlearn/models/src/src_*.sql - contains extra features such as checking for data freshness
- to define models as source, create a separate
source.yml file under the src model directory dbtlearn/models/sources.yml
e.g.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| version: 2
sources:
- name: airbnb
schema: raw
tables:
- name: listings
identifier: raw_listings
- name: hosts
identifier: raw_hosts
- name: reviews
identifier: raw_reviews
loaded_at_field: date
freshness:
warn_after: {count: 1, period: hour}
error_after: {count: 24, period: hour}
|
- in
models/src/src_listings.sql instead of directly referencing the Snowflake table as AIRBNB.RAW.RAW_LISTINGS, it can now be abstracted to{{ source('airbnb', 'listings') }} using names listed in the source YAML file
e.g.
1
2
3
4
5
| with raw_listings as (
select * from {{ source('airbnb', 'listings') }}
)
-- continue code here
|
dbt compile checks template tags, and connections; dbt goes through models, YAML files, tests etc and checks if all references are correct
Source freshness
- in the source YAML file, these lines under
reviews define freshness1
2
3
4
| loaded_at_field: date
freshness:
warn_after: {count: 1, period: hour}
error_after: {count: 24, period: hour}
|
- this means
- give warning if there’s no data that’s less than an hour fresh
- return an error if there are no new data in 24 hours
dbt source freshness is the command to use to check the freshness
Snapshots
- Snapshots in dbt implement Type 2 SCD
- Path is as defined in the project YAML file, and consist of SQL files
1
| snapshot-paths: ["snapshots]
|
- example code
dbtlearn/snapshots/scd_raw_listings.sql
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| {% snapshot scd_raw_listings %}
{{
config(
target_schema = 'dev',
unique_key='id',
strategy='timestamp',
updated_at='updated_at',
invalidate_hard_deletes = True
)
}}
select * from {{ source('airbnb', 'listings') }}
{% endsnapshot %}
|
config line defines how and where to create the snapshot; in this example it is created as a new table in Snowflake AIRBNB.DEV.SCD_RAW_LISTINGSinvalidate_hard_deletes = True means that if the record is deleted, dbt will replace the dbt_valid_to date to the snapshot date; if equals to False, it will not capture the delete- the table is materialized with additional columns
dbt snapshot takes the snapshots
- as records are updated in the raw table, the SCD table captures the changes as new rows with the
dbt_valid_to fields updated
Tests
- There are two kinds of tests in the dbt
- singular
- SQL queries stored in the
tests folder - the expected result set is empty
- generic
- built-in tests from the core installation of dbt
- unique
- not_null
- accepted_values
- relationships - takes a column value and makes sure it is a valid reference to records in another table
- custom tests and tests imported from dbt packages
unique and not_null are built in warehouse databases but may not be present in newer types like data lake or lakehousesdbt test runs the tests
Singular tests
- SQL in
tests folder e.g. dbtlearn/tests/dim_listings_minimum_nights.sql - example
1
2
3
4
5
6
| select
*
from
{{ ref('dim_listings_cleansed') }}
where minimum_nights < 1
limit 10
|
dbt test --help brings up the docsdbt test --select dim_listings_cleansed - runs the tests associated with the dim_listings_cleansed model only
Generic tests
- define
schema.yml under models folder- name does not matter; can be one file or several files
- can be used for extra configurations, tests, documentation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| version: 2
models:
- name: dim_listings_cleansed
columns:
- name: listing_id
tests:
- unique
- not_null
- name: host_id
tests:
- not_null
- relationships:
to: ref('dim_hosts_cleaned')
field: host_id
- name: room_type
tests:
- accepted_values:
values: ['Entire home/apt',
'Private room',
'Shared room',
'Hotel room']
|
Custom generic tests
- macros with special signature
- example
dbtlearn/macros/positive_value.sql1
2
3
4
5
6
7
8
| {% test positive_value(model, column_name) %}
select
*
from
{{ model }}
where
{{ column_name }} < 1
{% endtest %}
|
- add these in
schema.yml under model
1
2
3
4
5
6
7
8
9
10
| version: 2
models:
- name: dim_listings_cleansed
columns:
- <other tests here>
- name: minimum_nights
tests:
- positive_value
|
Macros
- Jinja templates created in the
macros folder - can be used in model definitions and tests
test is a special macro for implementing generic tests
- example:
dbtlearn/macros/no_nulls_in_columns.sql- in the for loop means remove whitespaces
1
2
3
4
5
6
7
| {% macro no_nulls_in_columns(model) %}
select * from {{ model }} where
{% for col in adapter.get_columns_in_relation(model) -%}
{{ col.column}} is null or
{% endfor %}
FALSE
{% endmacro %}
|
- use in
dbtlearn/tests/no_nulls_in_dim_listings.sql1
| {{ no_nulls_in_columns(ref('dim_listings_cleansed')) }}
|
Third-party packages
- extend dbt using dbt packages; allows access to a plethora of macros and tests
- go to
hub.getdbt.com - example
dbt-utils > generate_surrogate_key- “cross-database way” if the field values are the same in two or more instances of the database (even if different types of databases), the hash will still be the same
to install:
- create a file in the dbt project root directory called
dbtlearn/packages.yml
1
2
3
| packages:
- package: dbt-labs/dbt_utils
version: 1.3.0
|
- run
dbt deps to install- might not work behind firewall
- work around: go to the GitHub repository of the package, copy it manually to the dbt packages folder
dbtlearn/dbt_packages
- example of usage:
dbtlearn/models/fct/fct_reviews.sql
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| {{
config(
materialized = 'incremental',
on_schema_change = 'fail'
)
}}
with src_reviews as (
select * from {{ ref('src_reviews') }}
)
select
{{ dbt_utils.generate_surrogate_key(['listing_id', 'review_date', 'reviewer_name', 'review_text'])}} as review_id,
* from src_reviews
where review_text is not null
{% if is_incremental() %}
and review_date > (select max(review_date) from {{this}})
{% endif %}
|
- run
dbt run --select fct_reviews --full-refresh - specify full refresh so that the run doesn’t error out on_schema_change review_id has been added to the table in Snowflake
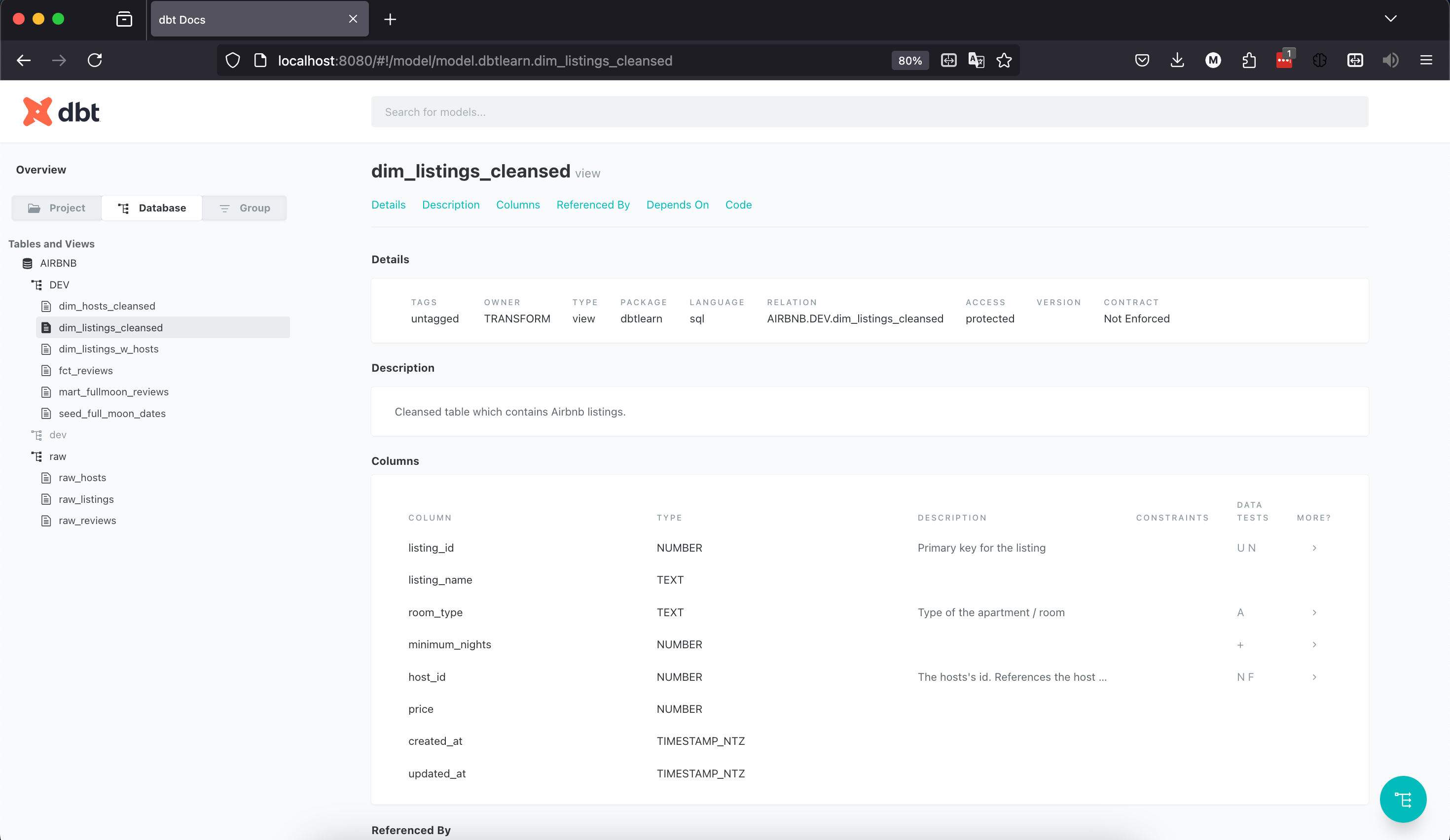
Documentation
- Should be kept close to the actual code as possible
- Defined in two ways
- in YAML files (e.g.
schema.yml) - in stand alone markdown files
- dbt combines these documentations in an html service that can be used on your own server
- otherwise, dbt ships with a lightweight documentation web server
overview.md is a special file that can be used to customize landing pages- dbt can also be configured to store assets like downloadables and images in a special folder that can be referenced in a markdown file
Basic documentation
- update
schema.yml to add descriptions
1
2
3
4
5
6
7
8
9
10
11
12
| version: 2
models:
- name: dim_listings_cleansed
description: Cleansed table which contains Airbnb listings.
columns:
- name: listing_id
description: Primary key for the listing
tests:
- unique
- not_null
|
- run
dbt docs generate to generate docs at target folder- catalog will be written to
dbtlearn/target/catalog.json - html in
dbtlearn/target/index.html
- run
dbt docs serve to render the documentation in the built-in dbt webserver
Markdown-based docs, custom overview page, and assets
- create a markdown file e.g. in the
models directory dbtlearn/models/docs.md
1
2
3
4
5
6
| {% docs dim_listing_cleansed__minimum_nights %}
Minimum number of nights required to rent this property.
Keep in mind that old listings might have `minimum_nights` set to 0 in the source tables. Our cleansing algorithm updates this to `1`.
{% enddocs %}
|
- add to description in
schema.yml
1
2
3
4
| - name: minimum_nights
description: '{{ doc("dim_listing_cleansed__minimum_nights") }}'
tests:
- positive_value
|
- can also create an overview doc in
dbtlearn/models/overview.md, e.g.
1
2
3
4
5
6
7
8
9
| {% docs __overview__ %}
# Airbnb pipeline
Hey, welcome to our Airbnb pipeline documentation!
Here is the schema of our input data:

{% enddocs %}
|
- to reference assets locally, add a folder in the project root
assets- make sur to define this path in
project.yml
1
| asset-paths: ["assets"]
|
- replace the url path in the markdown file e.g.
1
2
3
4
5
6
7
8
9
| {% docs __overview__ %}
# Airbnb pipeline
Hey, welcome to our Airbnb pipeline documentation!
Here is the schema of our input data:

{% enddocs %}
|
- running
dbt docs generate will generate the assets into target folder e.g. target/assets/input_schema.png
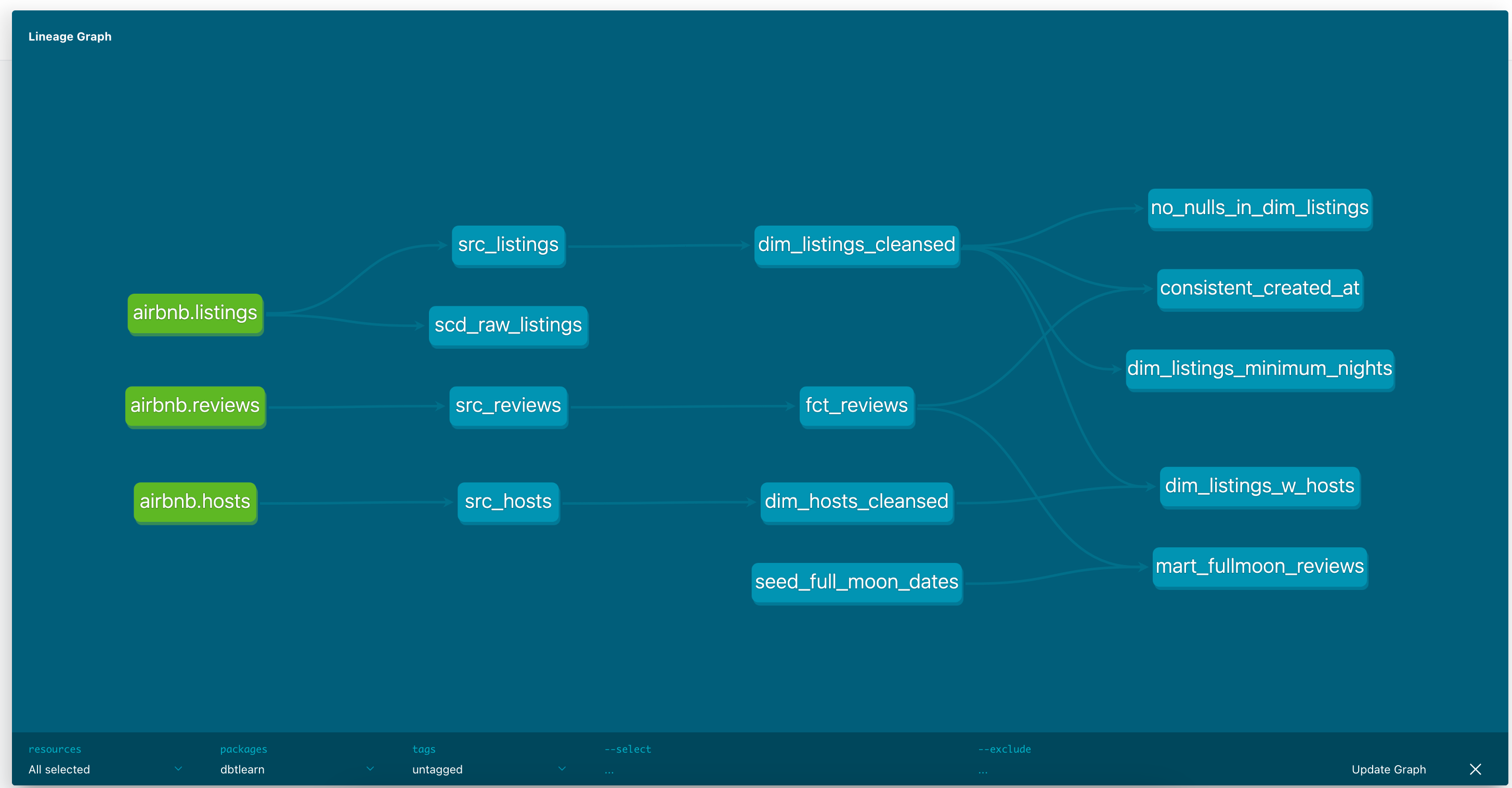
Lineage graph (data flow DAG)
- the lineage graph is accessible in the docs UI
- can set filter in the UI e.g.
--select +src_hosts++ preceeding src_hosts - show dependencies+ after src_hosts - everything that builds on src_hosts
--exclude dim_listings_w_hosts+- hide dim_listings_w_hosts and everything that depends on it
- can also use these filters in other dbt commands
dbt run --help e.g.- e.g.
dbt run --select src_hosts+- src_hosts and every model that builds from src_hosts will execute
Analyses
- can run a query using dbt syntax and references but not necessarily create a model
- version control, and execute against the data warehouse
- e.g.
dbtlearn/analyses/full_moon_no_sleep.sql
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| with mart_fullmoon_reviews as (
select * from {{ ref('mart_fullmoon_reviews') }}
)
select
is_full_moon,
review_sentiment,
count(*) as reviews
from
mart_fullmoon_reviews
group by
is_full_moon,
review_sentiment
order by
is_full_moon,
review_sentiment
|
- run
dbt compile - parsed SQL will be written to target e.g.
dbtlearn/target/compiled/dbtlearn/analyses/full_moon_no_sleep.sql which can be run in the data warehouse
Hooks
- SQLs that are executed at predefined times
- can be defined at project, models directory, or individual models level
- there are four types of hooks
- on_run_start: executed at the start of
dbt {run, seed, snapshot} - on_run_end: executed at the end of
dbt {run, seed, snapshot} - pre-hook: executed before a model/seed/snapshot is built
- post-hook: executed after a model/seed/snapshot is built
e.g. add a REPORTER role in Snowflake, initially this role does not have access to dbt views and tables
- in project yaml, add hook under models
- this will run for all models
{{ this }}
1
2
| +post-hook:
- "GRANT SELECT ON {{ this }} TO ROLE REPORTER"
|
- run
dbt run to execute the models - then go to Snowflake to check that the reporter role has select permission on all tables and views from dbt
Exposure
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| version: 2
exposures:
- name: executive_dashboard
label: Executive Dashboard
type: dashboard
maturity: low
url: <url to dashboard here>
description: Executive Dashboard about Airbnb listings and hosts
depends_on:
- ref('dim_listings_w_hosts')
- ref('mart_fullmoon_reviews')
owner:
name: M
email: email@example.com
|
- run
dbt docs generate then dbt docs serve - the exposures also appear in the lineage graph
dbt-expectations
Great Expectations
- data testing framework
- provides a bunch of functions that can be applied to a data
dbt-expectations
- not a port of Great Expectations in dbt but inspired by it
- see Available tests
- to install, add to
project.yml, and run dbt deps
1
2
3
| packages:
- package: calogica/dbt_expectations
version: 0.10.1
|
examples
- comparing row counts between models
- add to
schema.yml - run
dbt test --select dim_listings_w_hosts to only run test for this model
1
2
3
4
| - name: dim_listings_w_hosts
tests:
- dbt_expectations.expect_table_row_count_to_equal_other_table:
compare_model: source('airbnb', 'listings')
|
- looking for outliers in your data
1
2
3
4
5
6
7
| columns:
- name: price
tests:
- dbt_expectations.expect_column_quantile_values_to_be_between:
quantile: .99
min_value: 50
max_value: 500
|
- implementing test warnings
- note that
config can be set on any tests not just here
1
2
3
4
| - dbt_expectations.expect_column_max_to_be_between:
max_value: 5000
config:
severity: warn
|
- validating column types
- uses the types of backend (in this case Snowflake)
1
2
| - dbt_expectations.expect_column_values_to_be_of_type:
column_type: number
|
- monitoring categorical variables in the source data
- add to
sources.yml file - to run a test for a source, run
dbt test --select source:airbnb.listings- also runs tests that affect the source table e.g.
dbt_expectations_source_expect_column_distinct_count_to_equal_airbnb_listings_room_type__4 dbt_expectations_expect_table_row_count_to_equal_other_table_dim_listings_w_hosts_source_airbnb_listings_
1
2
3
4
5
6
7
8
9
10
11
12
13
| version: 2
sources:
- name: airbnb
schema: raw
tables:
- name: listings
identifier: raw_listings
columns:
- name: room_type
tests:
- dbt_expectations.expect_column_distinct_count_to_equal:
value: 4
|
Debugging
Debugging dbt tests
dbt --debug test --select source:airbnb.listings- for debugging, will see all the SQLs that dbt runs against the data warehouse in the terminal screen which can get overwhelming
- or check the compiled SQL in the target folder
target/compiled/dbtlearn/models/sources.yml/dbt_expectations_source_expect_a60b59a84fbc4577a11df360c50013bb.sql- this can be executed in Snowflake for further debugging
Debugging and working with regular expressions
- e.g. regex for price $90.00
$ and . need to be escaped for regex, then escaped for YAML, then need to be escaped twice so the slashes actually render in Snowflake; these happens when there are many interconnected technologies- use the compiled SQL command in
targets directory to debug the regex in Snowflake
1
2
3
4
5
6
7
8
9
10
11
| sources:
- name: airbnb
schema: raw
tables:
- name: listings
identifier: raw_listings
columns:
- name: price
tests:
- dbt_expectations.expect_column_values_to_match_regex:
regex: "^\\\\$[0-9][0-9\\\\.]+$"
|
Logging
- can log messages to dbt’s standard log file, or the terminal, or disable a log message temporarily
Logging to the dbt log file
- create a macro
dbtlearn/macros/logging.sql - run the macro
dbt run-operation learn_logging - this will be logged in the logging file
dbtlearn/logs/dbt.log as [debug] - can add this Jinja command anywhere e.g. in the middle of a SQL command
1
2
3
| {% macro learn_logging() %}
{{ log("This is a logging message from the macro") }}
{% endmacro %}
|
Logging to screen
- add a second paramater
info=True - message will appear on the screen, and also in the dbt log file as
[info]
[0m21:08:00.947064 [info ] [MainThread]: This is a logging message from the macro
Disabling log messages
- there are two layers of execution in dbt
- when macro is executed, the jinja will be executed
- then the SQL from Jinja will be executed
- so to comment out a log, use a Jinja comment tag
# instead of sql comment tag --- ❌
-- {{ log("This is a logging message from the macro", info=True) }} - ✅
{# log("This is a logging message from the macro", info=True) #}
1
2
3
| {% macro learn_logging() %}
{# log("This is a logging message from the macro", info=True) #}
{% endmacro %}
|
Variables
There are two kinds
- Jinja variables
- define and use them in Jinja
- dbt variables
- dbt specific-variables which can be passed to dbt through the command line or the project YAML
Jinja variables
- can be defined using
set - e.g. create a macro in
dbtlearn/macros/variables.sql
1
2
3
4
5
6
| {% macro learn_variables() %}
{% set your_name_jinja = "FooBar" %}
{{ log("Hello " ~ your_name_jinja, info=True) }}
{% endmacro %}
|
dbt variables
- aka Project variables
- variables that dbt manages for you
- pass their values from the command line or project YAML
1
2
3
4
5
| {% macro learn_variables() %}
{{ log("Hello dbt user " ~ var("user_name") ~ "!", info=True)}}
{% endmacro %}
|
- in commandline, specify the username
dbt run-operation learn_variables --vars "{user_name: foobar}"
Setting default values
- can be set in
var() but would need to set default value whenever you set the variable
1
2
3
4
| {% macro learn_variables() %}
{{ log("Hello dbt user " ~ var("user_name", "NO USERNAME IS SET") ~ "!", info=True)}}
{% endmacro %}
|
- another way is to define the default value in project YAML file
- will overwrite default in macro if no
user_name is passed in the command line
1
2
| vars:
user_name: default_user_name_for_this_project
|
Using data ranges to make incremental models production-ready
- standard practice to use parameterization for data ranges to backfill
- check variable existence
{% if var("start_date", False) and var("end_date", False) %} - update
dbtlearn/models/fct/fct_reviews.sql below
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| {{
config(
materialized = 'incremental',
on_schema_change = 'fail'
)
}}
with src_reviews as (
select * from {{ ref('src_reviews') }}
)
select
{{ dbt_utils.generate_surrogate_key(['listing_id', 'review_date', 'reviewer_name', 'review_text'])}} as review_id,
* from src_reviews
WHERE review_text is not null
{% if is_incremental() %}
{% if var("start_date", False) and var("end_date", False) %}
{{ log('Loading ' ~ this ~ ' incrementally (start_date: ' ~ var("start_date") ~ ', end_date: ' ~ var("end_date") ~ ')', info=True) }}
AND review_date >= '{{ var("start_date") }}'
AND review_date < '{{ var("end_date") }}'
{% else %}
AND review_date > (select max(review_date) from {{ this }})
{{ log('Loading ' ~ this ~ ' incrementally (all missing dates)', info=True)}}
{% endif %}
{% endif %}
|
- if this is not an incremental load (full refresh), or if it is but has no start date and end date parameters, proceed as the naive implementation i.e.load review date src to fct model if review is not null and review date is after the max date
- if this is an incremental load but has a start date and end date, then include extra conditions of having the review date in between start date and end date
dbt run --select fct_reviews
1
| 12:53:32 Loading AIRBNB.DEV.fct_reviews incrementally (all missing dates)
|
dbt run --select fct_reviews --vars '{start_date: "2024-02-15 00:00:00", end_date: "2024-03-15 23:59:59"}'
1
| 2:54:46 Loading AIRBNB.DEV.fct_reviews incrementally (start_date: 2024-02-15 00:00:00, end_date: 2024-03-15 23:59:59)
|
- review compiled code
dbtlearn/target/compiled/dbtlearn/models/fct/fct_reviews.sql and it would have the date ranges
1
2
3
4
5
| -- code above
WHERE review_text is not null
AND review_date >= '2024-02-15 00:00:00'
AND review_date < '2024-03-15 23:59:59'
|
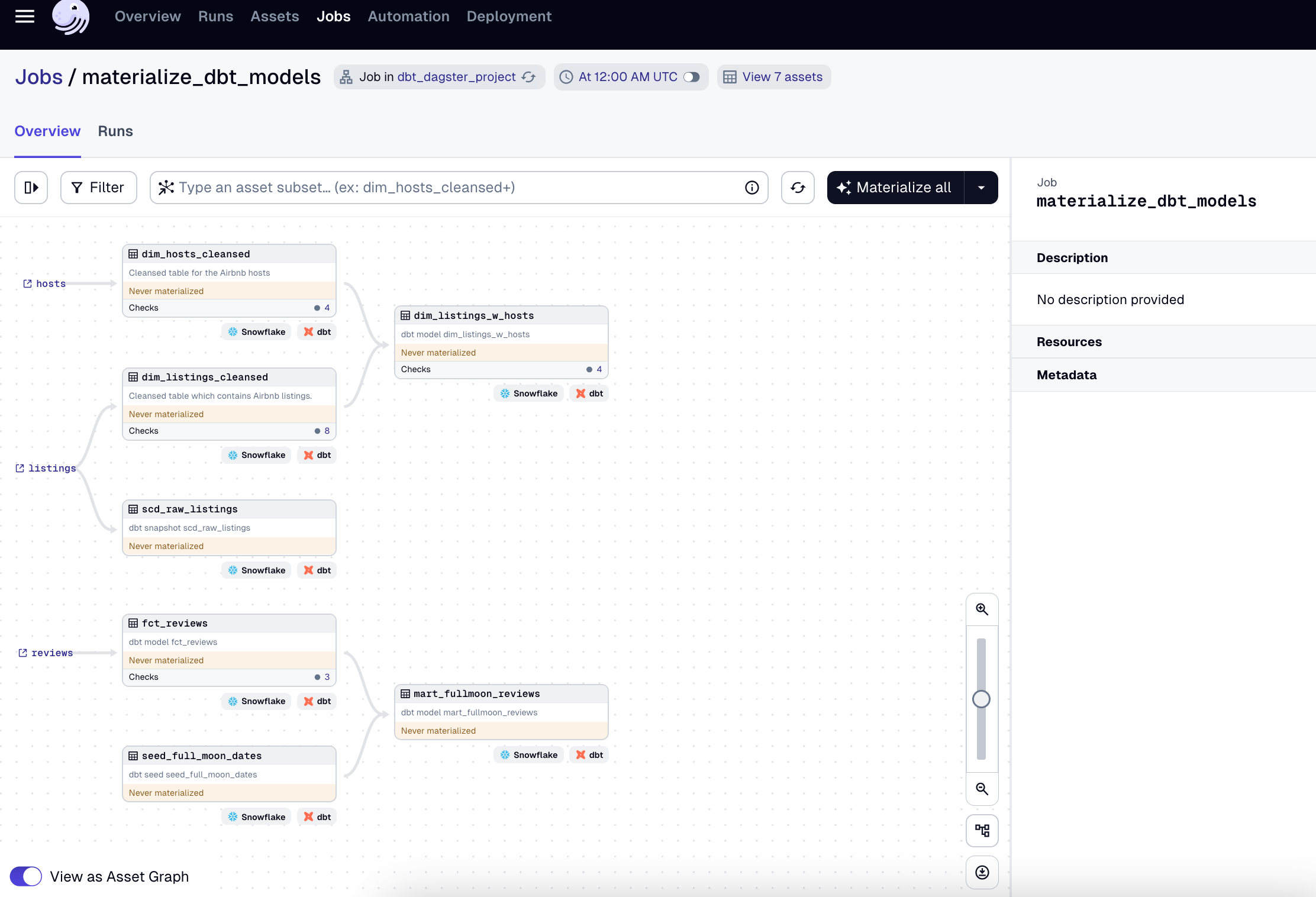
Orchestrating dbt with dagster
Integrate with other orchestration tools
- Airflow
- large community; many answers out there
- installation is a bit difficult
- does not really integrate well with dbt other than building the models
- manages the whole dbt workflow as a unit
- Prefect
- more modern ETL tool
- easy to install; very Pythonic
- simple integration with dbt
- doesn’t have full-fledge integration although better than Airflow
- Azure Data Factory
- point and click
- good product in itself but doesn’t really have tight integration with dbt
- dbt Cloud
- proprietary offering from dbt Labs
- dagster
- new generation scheduling tool
dagster
- very tight dbt integration; understands dbt project well
- data concept of dagster (asset) is similar to dbt (model)
- great UI
- easy to debug - will see exactly what dagster executed when you execute the workflow
dagster installation
- create a
requirements.txt and pip install -r requirements.txt into a virtual environment
1
2
3
| dbt-snowflake
dagster-dbt
dagster-webserver
|
- create a dagster project from existing dbt project
dagster-dbt project scaffold --project-name dbt_dagster_project --dbt-project-dir=dbtlearn
- before launching dagster, make sure that dbt connections are ok and that the dependencies in dbt have been installed
1
2
3
| cd dbtlearn
dbt debug
dbt deps
|
add a schedule into the dagster project dbt_dagster_project/dbt_dagster_project/schedules.py, remove the comment in schedules
start the dagster project
1
2
| cd 'dbt_dagster_project'
dagster dev
|
Here are some resources about dagster
Advance Power User dbt core
Here are some advance features using the Power User dbt core extension.
To get the API key, sign up to Altimate.ai. The key is free with the free account sign up. UI will show the API key and instance name which need to be added to the extension in the settings file in VS Code.
With the AI integration, the features now include:
- Generate documentation
- Generate dbt model from source definition or SQL
- Column level lineage
- Generate dbt tests
- Check the health of the dbt project
- Query explanations
- dbt project governance using the open source python package datapilot-cli
- Query translation between SQL dialects
Introducing dbt to the company
As for introducing dbt to the company, I find these tips from the interview interesting:
- Approach it as an experimentation rather than a business case. Experimentation means you’re going to try if it’s a good fit or not. This would also put less pressure on the team and give them time to learn the tool and find out if they like it or not – rather than introducing it as a business case wherein it’s presented as the solution.
- Involve the business in workshops to give them opportunities to ask questions, and see if the solution is able to give answer and/or spark discussions. It helps to have a data steward that can bridge the engineering team with the business domain.
- Act in stages. Stage 1 is all about the business perspective - it needs to address a problem; if successful go to Stage 2. This stage is the technical phase - how can dbt fit in the current stack, are additional infrastructure needed, are there added security measures or compliance issues etc.
- Work on a POC e.g. migrate a data mart to dbt and evaluate the value from that; 3-months is a good timeline. Helps if the team can work with an external consultant proficient in dbt.
Characteristics of dbt that makes it easy to recommend
- Python ecosystem; lightweight, easy to put into production (containerized) and integrate into CI/CD
- Lineage, documentation as first class citizen in dbt makes it easy to own the pipelines (ownership involves being able to answer questions about where the data came from, how it’s transformed, where it was published )
- Modular approach breaks down large stored proc into interconnected models which can make good points of discussions (about the business logic) and helps with maintenance
- dbt abstracts the technicalities like parallelization, dependency of models, optimization of execution, so developers can focus on the logic and model building
dbt Certifications
There are currently two exams: one for analytics enginer, and one for cloud administrator. Details here.
Some tips from the interview:
- It was useful to do the Udemy course as an introduction to dbt.
- It helps if you’ve practiced dbt for a while before taking the exam, although not impossible to pass without it.
- Do a lot of practice questions.
- Questions include multiple choice, scenario-based, git, and dbt flags.
- Most questions are about dbt core not dbt cloud.
Resources